During OpenAI's o3 model unveiling in December 2024, Chief Research Officer Mark Chen stated the model achieved 'over 25%' on the FrontierMath benchmark. When Epoch AI—the organization that created FrontierMath—independently tested the publicly released o3 in April 2025, they measured approximately 10%. Less than half.
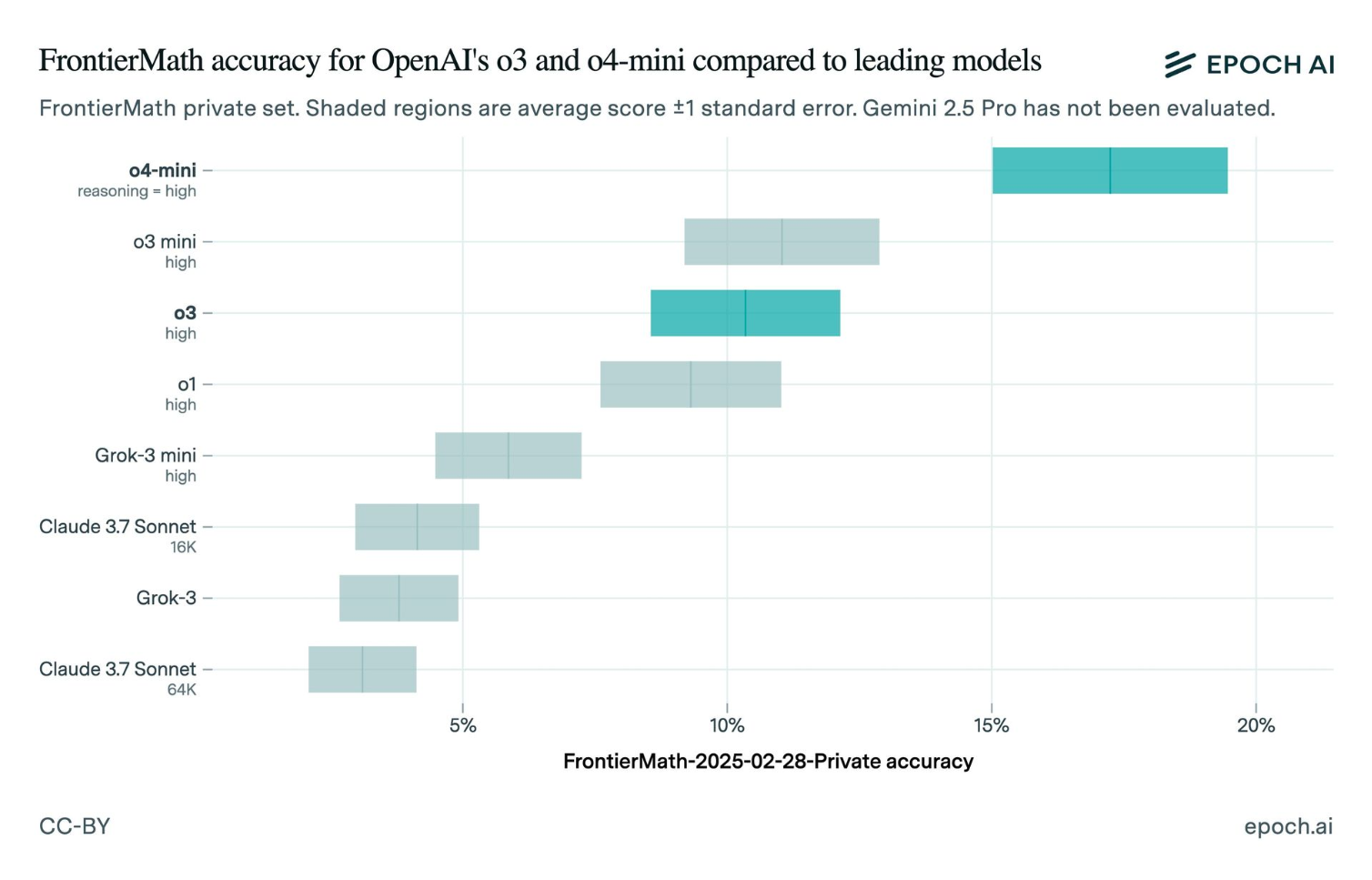
Chart source: TechCrunch & Epoch AI Testing
The Violation
- 1
Announced score of 25%+ based on internal high-compute configuration
- 2
Public release scored ~10% on same benchmark when independently tested
- 3
No clarification during announcement that quoted score required unavailable compute settings
- 4
15 percentage point gap between claimed and delivered performance
Why This Matters
When customers evaluate AI models based on benchmark claims, they assume the scores reflect the model they'll actually receive. Advertising results from an internal high-compute version while releasing a lower-performing public version misleads purchasing and deployment decisions.
Community Verdict
"OpenAI's o3 AI model scores lower on a benchmark than the company initially implied. This is a significant credibility issue."
"We tested the publicly available o3 model and got approximately 10% on FrontierMath, not the 25%+ OpenAI announced. There's a major discrepancy."
The Defense
Imagined company response
"OpenAI has not issued a formal statement addressing the discrepancy. The company's documentation does note that o3 performance varies significantly with compute budget, but this was not emphasized during the launch announcement."
Spot a similar crime?
Help us document chart crimes in the wild