Meta's Llama 4 launch in April 2025 touted impressive LM Arena rankings. Independent analysis revealed the model submitted for public benchmarking used optimization techniques and configurations that weren't available in the version released to developers.
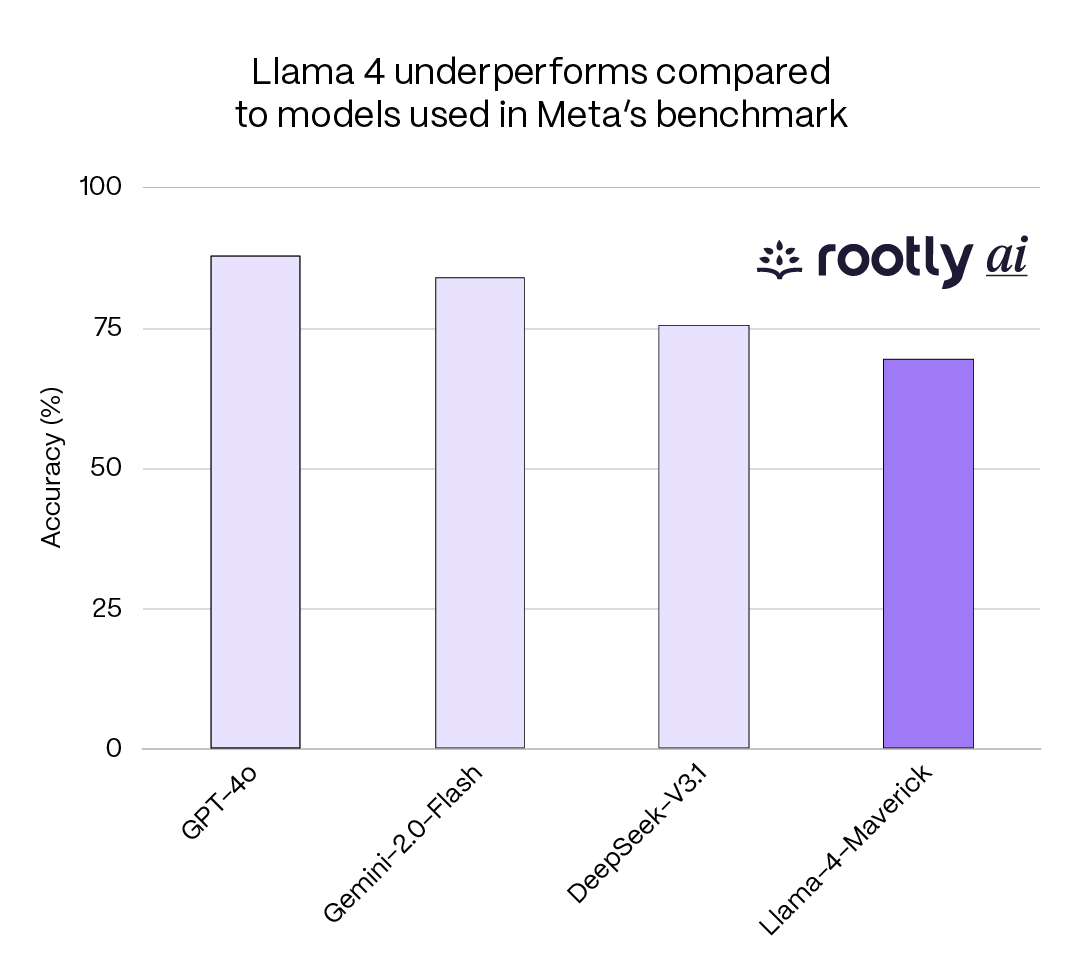
Chart source: Meta AI Blog
The Violation
- 1
Benchmark version used experimental optimizations not in production release
- 2
Public leaderboard scores reflected enhanced configuration unavailable to users
- 3
No disclosure in announcement materials about configuration differences
- 4
Performance gap between benchmarked version and released version not quantified
Why This Matters
Benchmarks exist to help developers and enterprises make informed decisions about which models to deploy. When the benchmarked version differs from the available version, those decisions are based on misleading information. It's like test-driving a V8 then purchasing a V6.
Community Verdict
"The Llama 4 on LM Arena was clearly running with settings we can't replicate. Meta needs to clarify what was actually tested vs what shipped."
"This is becoming standard practice: optimize for the benchmark, ship something different. We need benchmark submissions to match release versions."
Spot a similar crime?
Help us document chart crimes in the wild